|
|
|
| This document is available in: English Castellano ChineseGB Deutsch Francais Italiano |
![[Photo of the Author]](../../common/images2/RalfWieland2.jpg)
by Ralf Wieland <rwielandQzalf.de> 关于作者: 我通过编程来研究环境仿真、神经网络何模糊系统。后者就是在 linux 下进行的(自从版本 0.99pl12 开始)。而且,我对电子何硬件很感兴趣,我尽量在 linux 完成相关的工作。 目录: |
Linux 在科学界 --- 开发了一个多强大的神经网络工具啊!![[Illustration]](../../common/images2/article345/symbol.png)
摘要:
本文演示了基于 linux 的科学计算软件的可用性。文中特别描述了空间仿真的科学工具的开发。作为一个例子,我们将介绍一个以 GPL 发布的软件--- neural network simulator (神经网络仿真器)。
|
我工作在一个研究环境的研究所 研究这样的问题:
日常的工作包括数据分析、剔除错误数据、整理不同的数据格式、书写报告等,这些工作都极大地得益于 Linux 的使用。尽管有些人更信赖 Excel 和那些“万能软件”,但 Perl、Emacs、 octave [www.octave.org], R [www.r-project.org] 等工具的组合被证明在和大量数据的斗争中是胜利者。Perl 是一个多面手,它不仅擅长数据的转换,还可以查询数据库 (MySQL), 进行计算等,并且快速而可重复执行。特别地,后者(可重复执行)在仿真工作中尤其重要,因为手工工作十分容易出错,而使用验证过的脚本就很少发生错误。使用 LaTeX 书写文章可以方便地得到很高的输出质量。Linux 提供了很多对科学工作十分有吸引力的工具,毕竟不是所有的事情都可以通过直觉完成,也不是所有人都是编程怪物。
一个人为什么要自己开发所有的东西呢?难道已有的不能用吗?高性能的仿真工具,像 Matlab [www.mathworks.com],是可用的。 要处理地理数据可以用像ARCGIS [www.esri.com/software/arcgis] 或自由软件 Grass [grass.itc.it] 这些地理信息系统 (GIS)。对于统计,也是如此。这样一来,为什么还要几许开发呢?
问题不在于单个软件的性能,而是要把它们整合成一个系统。在仿真中,子任务不得不由不同的程序完成,这些程序之间的通信可能只能使用非常笨重的用户定义的接口。更让人恼火的是可用的数据是大块的高错误率的数据。为此,必须要有大量的仿真次数。一个算法必须能够得到有用的结果,即使所输入的数据不全符合需要,在这种情况下应该给出一个警告。在处理大量数据(常常是包含上百万元素的矩阵)的时候,需要有快速的算法。健壮快速的算法往往只能由研究者们自己来实现。
商业系统的显著缺点是源代码保密。这样一来科学家如何开发和交换模型呢?因此,我们绝顶开发一个开放源代码软件---空间分析与建模工具(SAMT, Spatial Analysis and Modeling Tool)。
这是一个仿真工具,也包含空间数据的数据管理和对 MySQL 数据库和 GIS 系统的接口。它包含光栅数据管理的基础函数,它能处理光栅(混合、距离、内插等),并能生成二维或三维的数据表达。
注意:光栅数据是基于把一个图分到小方格中得到的。信息存储在若干层中。除了更深入地接近信息,同一层内周边的信息也很重要。后者是 lateral material flows 建模的基础,常见于风和水导致的土壤侵蚀现象中。
SAMT 生成了一个框架,其中可以容纳各种工具,比如(超高速)模糊解释器和神经网络工具(nnqt)。模糊模型用于把专家知识加入到仿真之中来。一个专家常常可以在缺乏数学模型的情况下,描述一个过程甚至是控制这个过程。神经网络是一些过程,它们允许我们通过测量数据得到功能上的相关性。后文将会进一步介绍这个神经网络工具的开发。
一个人工神经网络包含很多层。第一层将被装入浮点格式的初始数据,用于训练模型。输入和输出之间的层在外界不是直接可见的,被称做‘隐藏层’。有时会有多个隐藏层。例子中的输出层只有一个元素。这种结构用于建立一个多入单出函数。对于非线性行为的映射,比如函数 x^2-y^2,隐藏层是必不可少的。网络是如何知道目标函数的呢?当然,初始情况下,网络并不知道。元素(节点)间的连接(重量)首先是随机的。在训练序列中,学习算法尽力改变重量,使得计算的输出和预知的输出的均方误差最小化。有很多不同的算法来达到这个目的,我们不想实现每个算法。在 nnqt 中,我们实现了三个算法。为了特定输出而制定的输入的过程也称为“监控学习 (supervised learning)”。
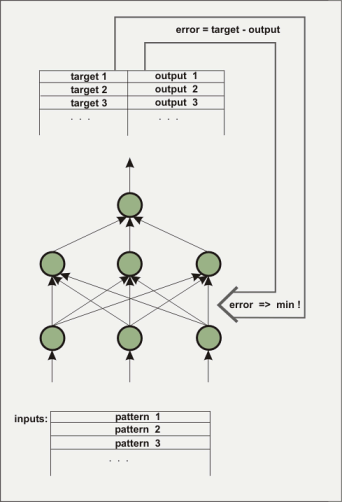
我们需要训练网络以达到一个对训练数据、同样也是对控制数据的足够小的误差(使用部分训练队列当作控制数据来验证学习的性能是个明智的作法)。连接的重量确定了网络的行为,它们被以这种目的存储起来。这样一个网络能用做什么呢?除了科学界中用于建模工具以外,还有很多各种正式或非正式的用途。比如预测股市走势。当然我没成功做过股市预测,不过其他人可能成功过。
另一个有趣的可能性是使用神经网络进行短期天气预报。比如说,电子气象站的数据可以被用于训练一个神经网络。有用的数据包括气压及其变化,以及降水。电子气象站里的符号是这样的形式。一个神经网络能做得更好吗?要支持自己的实验,您可以用 nnqt,这是一个 GPL 软件。
科学家们首先以分析他们采集的数据为需求开始了神经网络工具的开发。他们需要一个尽可能简单的工具,这个工具应该可以被空间应用所立用,也就是说:他们希望看到结果和空间位置的关系。当然,市场上已经有了很多优秀的神经网络工具了。即使是自由的工具,比如SNNS [www-ra.informatik.uni-tuebingen.de/SNNS/],或是自由的软件库,比如 fann [fann.sourceforge.net],也是可供选择的。SNNS 非常出色,但是它对于不会编程的人来说很难使用,因为它生成 C 源代码。在这个的领域中,SNNS 对于有这样的需求的用户是无法抗拒的。而nnqt面向如下的需求:
nnqt 的开发分为了如下几步:
有关神经网络的优秀文献不胜枚举。作为一个代表,这里提一本书,不过尽管如此,有时有的东西还是必须要通过经验的积累和交流才能得到。我本来很喜欢使用 Matlab 用 Levenberg-Marquardt 算法快速的工作。而通过在互联网上的广泛搜索,我读到了一篇 文章 [www.eng.auburn.edu/~wilambm/pap/2001/FastConv_IJCNN01.PDF][本地版本, 105533 字节],介绍了在神经网络中使用这种算法。以此为基础,我才开始把我钟爱的 tanh (tangens hyperbolicus) 函数加入到算法之中。而且,为此我使用了 Linux 软件:计算机代数系统 Maxima [maxima.sourceforge.net]。这类系统可以处理复杂的方程、计算微分、计算那些用纸笔不容易计算的操作。Maxima 使得进行那些处理成为可能,并可以在一个周末的时间里用 C 实现的算法的算法的第一个版本。C 的实现可以用做测试和参数的选择。通过使用开放源代码的仿真系统 desire [members.aol.com/gatmkorn] (非常感谢开发者 Korn 教授!) 进行比较,可以进行初始模型的计算。更新的实现算法做得不算太差。作为一个测试的例子,xor问题的训练时间对于 3GHz Pentium 计算机来说大约 70 毫秒。(大部分时间用于了读硬盘操作,在一台老的 Athlon 750MHz 计算机上的运行时间只稍长一点)。
作为一个替代选择,著名的back propagation算法也被实现、分析了。这些准备活动作为进一步改进算法的基础进行了之后,工具箱的实现工作继续进行。
我喜欢 qt 开发环境,它的文档非常好,并且我可以使用 Emacs 编辑器。qt designer 可以帮助我们设计界面,尽管这个选项不能满足 nnqt 开发的需要。我需要一些示意图、坐标之类的东西,对于这些,开发者社区再次提供了巨大的帮助。可以使用 qwt [qwt.sourceforge.net] 和 qwt3d [qwtplot3d.sourceforge.net] 库,这极大地缩短了开发周期。使用这些资源,nnqt 在大约两周之内就构建出来了。当我为这个结果欢欣鼓舞的时候,我转向了它的用户。他们又有了更多的需求!数据应该自动的分为训练集和测试集,他们希望能进行命名以为改进改进的组织,希望更多的分析--比如带参数的曲线图等。好了,有些东西我可以立刻加入,而其他的呢?会慢慢加入的。这是一些截屏:
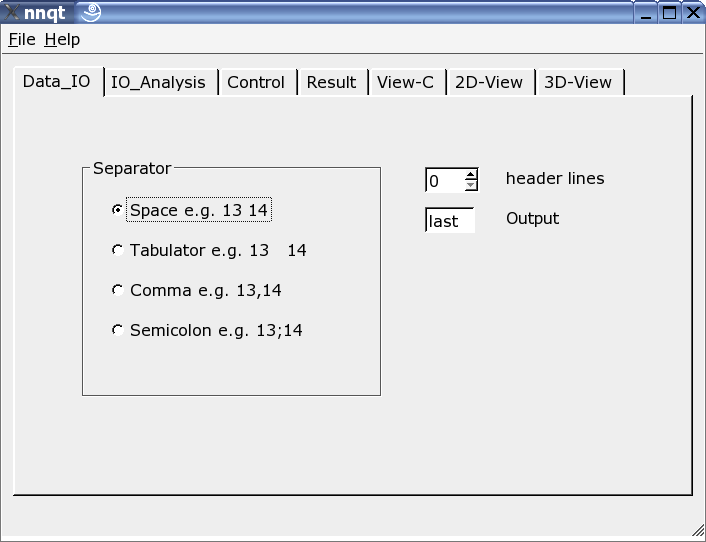
这里,reader 可以根据输入数据格式而调整。可以使用不同的Separator,有些开头的行可能被隐藏,或者数据集中的目标数据可以被随意的选择。注意:数据的格式应该是已知的,因为 nnqt 是依赖于用户输入的。
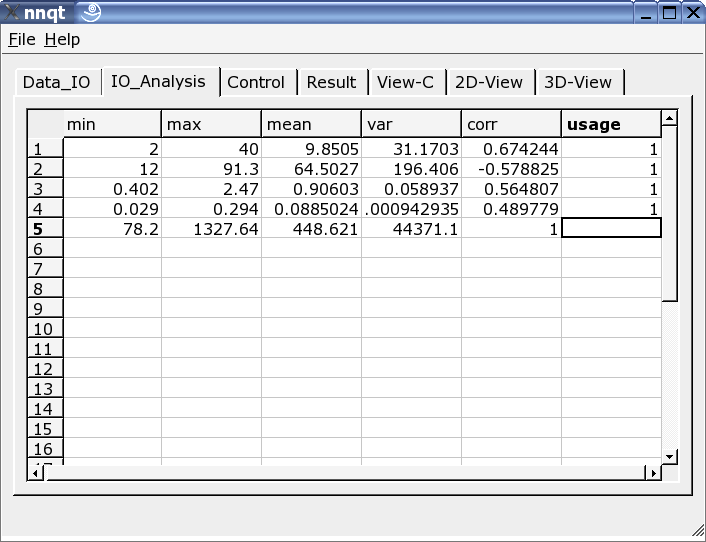
成功输入数据之后,我们直接进入数据分析页面。这里,我们从数据中找出一些信息,并从所有的列中选择训练数据。最后一列中的'1'标志者训练值的输入。(最多可以使用29个训练值。)
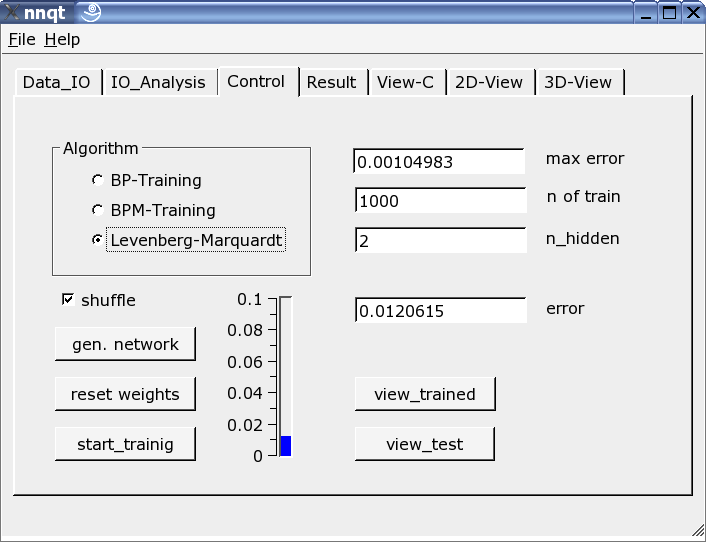
最重要的是控制面板。隐藏元素的个数,学习步数和训练算法都在这里设置。训练可以在纵轴上面以刻度和刻度值的形式体现出来。训练必须重复进行,因为初始参数是随机选择的,而结果和初始参数相关。选中"shuffle"列表框表示随机选择训练数据而不是顺序选择,有时会带来一些好处。如果我们我们成功地达到了足够低的均方误差,我们可以按"view_trained"按钮得到第一个图
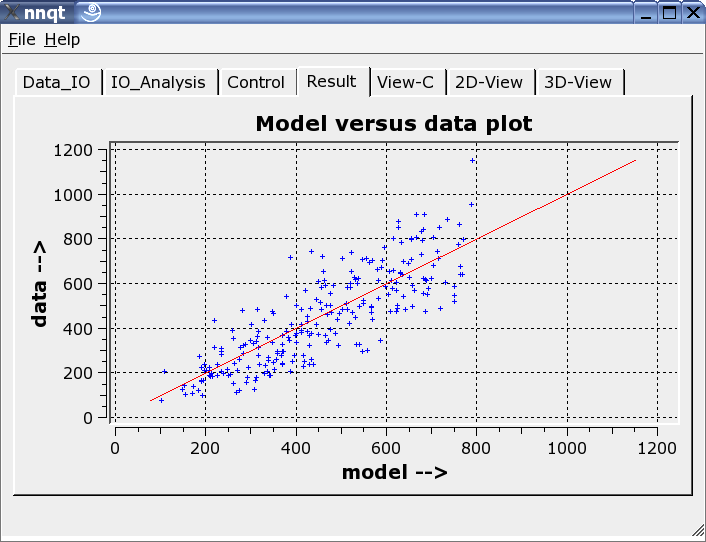
这张图显示了训练数据与神经网络生成的数据。理想状态下,数据应该在对角线上。但理想不可能被实现!不过,结果看起来还不错。(控制数据--也就是那些没有被训练的--被用红色标出来了。)下一步就可以分析功能的进行了。缺省值必须是一些特意选定的数。我们必须十分小心,因为网络只对于和训练数据接近的数据才是可靠的。
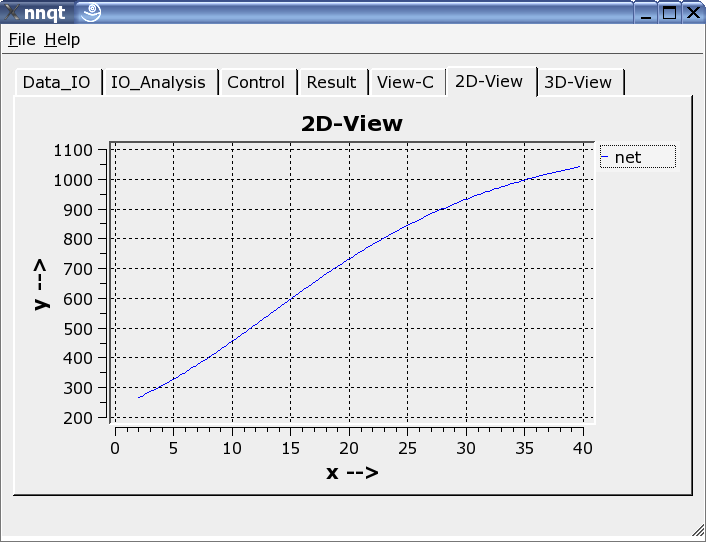
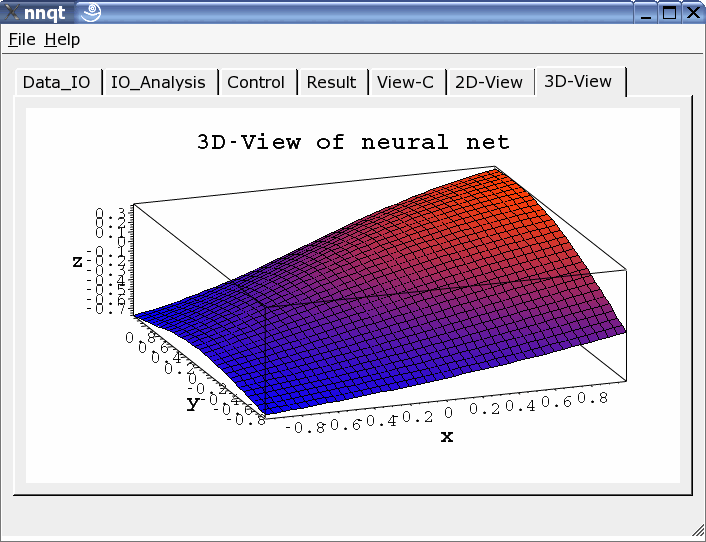
可以选择二维或是三维的表示
nnqt是开放源代码软件,在 GPL 下发布。任何人都可以自由地使用和修改它。后者更是特别重要的。安装非常简单。只有 qwt 和 qt 是必须预先安装的。nnqt.tgz直接解包 (tar-zxvf nnqt.tgz)。这将建立一个名为 nnqt 的新目录。进入目录cd nnqt 之后运行 qmake 和 make。如果一切正常的话,必须运行下面的命令来声明一个环境变量。
export NN_HOME=/pfad_zu_nnqt
如果 nnqt 在一个新的终端中被打开,数据和模型将被 nnqt 自动检测到。我希望你能从这里得到更多乐趣。为了检测程序,一个两输入数据集被加入到程序中了。有没有谁可以认出这个被学习的函数?(这是一个[-2..2]上的 x^2-y^2。)
使用它我们能创造出什么来--我拭目以待你的想法。
Linux 是一个杰出的解决科学问题的开发环境。我可以在优秀的软件的基础上开发,没有这些,我不可能在短短的6周中开发出有用的软件。能使用自由软件总是让人感到鱼脍的。对此非常感谢那些开发者,他们的工作使得我们能在 Linux 下完成的这些美妙的事情成为可能。
James A. Freeman:
"Simulating Neural Networks with Mathematica", Addison-Wesley
1994
|
主页由LinuxFocus编辑组维护
© Ralf Wieland "some rights reserved" see linuxfocus.org/license/ http://www.LinuxFocus.org |
翻译信息:
|
2004-10-14, generated by lfparser version 2.49